Wir kommen unserem Bibliothekskatalog in dieser Einheit schon wieder ein Stück näher und widmen uns dem vorletzten Arbeitsschritt zur Entwicklung unseres Discovery-Systems: Dem Indexieren.
Einführung Suchmaschinen
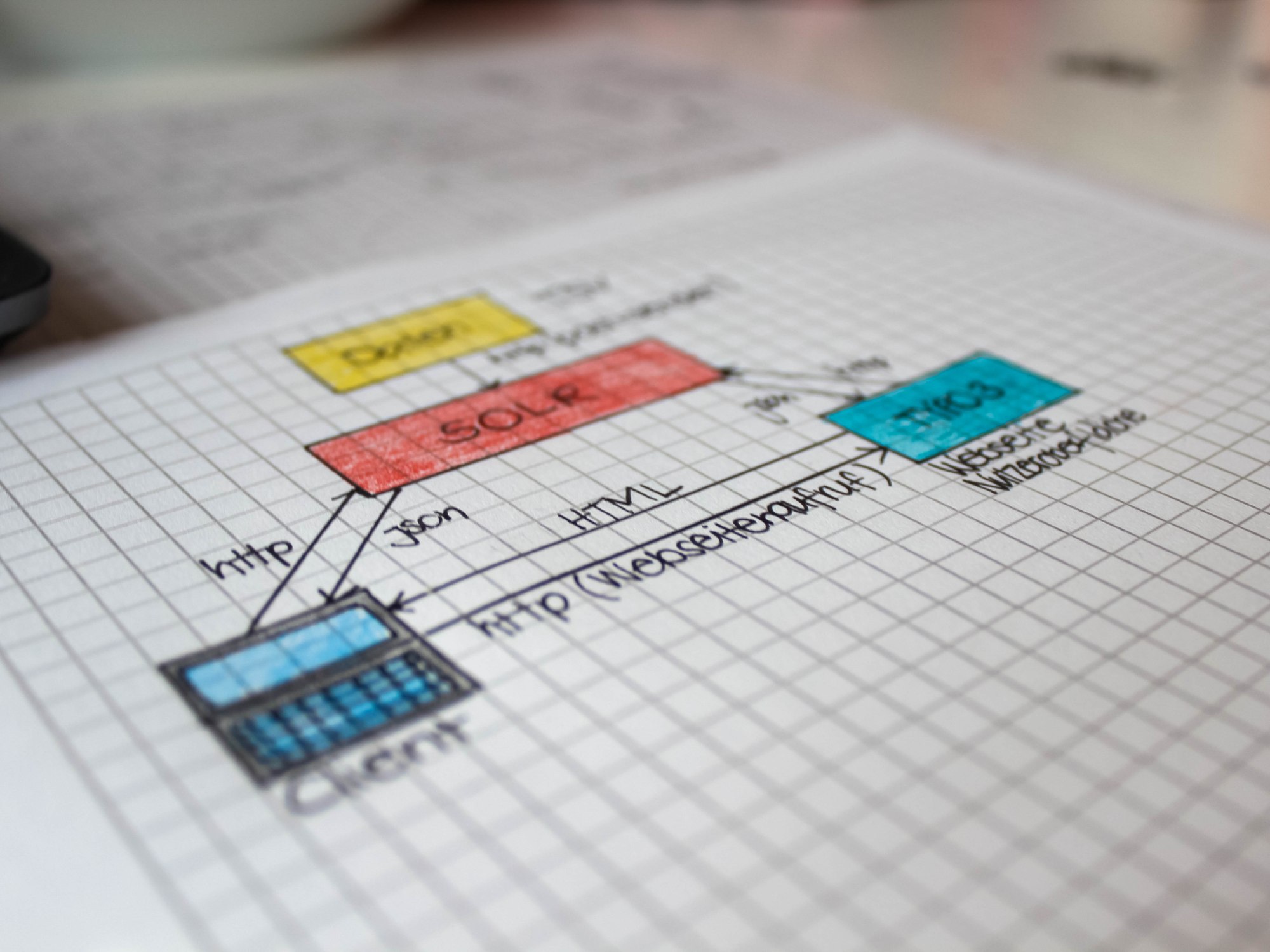
Um Indexieren zu können, brauchen wir eine Suchplattform, um die Daten indexieren und speichern zu können. Unser Dozent Felix Lohmeier hat uns hierfür kurz die zwei bekanntesten Suchmaschinen vorgestellt.
Beiden Suchmaschinen sind Open-Source Produkte. Deshalb gibt es bei beiden auch eine Open-Source Community, das heisst die Suchmaschinen werden stetig mithilfe der Nutzer verbessert und optimiert.
Für unser Disovery-System haben wir die Plattform Solr gewählt. Diese Plattform wird nicht nur in Bibliotheken angewendet, sondern auch von bekannten Unternehmen wie Netflix, Instagram, Adobe und Ticketmaster. Solr bietet ihren Nutzern unter anderem ein Relevanz-Ranking sowie eine Volltextsuche an, was optimal ist um ein gutes Discovery-System aufzubauen.
Repetition Open Refine
Wir haben unsere OpenRefine-Übung noch einmal mit dem überarbeiteten Kapitel 3.5 durchgespielt, da es beim letzten Mal etwas schnell voran ging. 😉 Bei diesem zweiten Durchgang kam ich gut mit und konnte die Übung zu meiner vollsten Zufriedenheit lösen.
Installation Solr
Nach dieser kurzen Einführung zu den zwei bekanntesten Suchmaschinen haben wir anhand des Kapitels 4.1 im Skript Solr im Terminal heruntergeladen.(Unter diesem Link findet man das offizielle Installationsanleitung von Solr)
Um die Grundlagen von Solr zu erarbeiten haben wir den Abschnitt „Basic Searching“ im offiziellen Solr Tutorial durchgearbeitet und uns mit dem dem Query-Interface vertraut gemacht. (Tutorial um Solr kennenzulernen)
Wir haben die Möglichkeit innerhalb einer Testversion/auf einer Testoberfläche zu arbeiten. Deshalb ist sie auch relativ technisch und einfach gestaltet, deshalb wirkt die Seite auch nicht zu überladen. Die Gestaltung ist sehr einfach schon fast langweilig, aber das trägt ebenfalls dazu bei, dass die Seite klar und übersichtlich wirkt. Ich arbeite selbst Teilzeit in einer Bibliothek und habe bei dieser Übung einige Funktionen von Bibliothekskatalogen gefunden, welche bereits in Solr integriert sind, wie z.B. Facetten, Relevanzranking.
Daten auf Solr laden
Anhand des Kapitel 4.3 haben wir die Daten auf Solr geladen.
Zuerst haben wir einen Index im Terminal erstellt mit folgendem Befehl:
~/solr-7.1.0/bin/solr create -c htwIm zweiten Schritt haben wir ebenfalls im Terminal die Daten aus Kap. 3.5 geladen. Dafür haben wir folgenden Befehl eingebeben:
curl "http://localhost:8983/solr/htw/update/csv?commit=true&separator=%09&split=true&f.creator.separator=%E2%90%9F" --data-binary @- -H 'Content-type:text/plain; charset=utf-8' < ~/Downloads/einstein.tsvDieser Befehl indexiert die Daten aus der Datei einstein.tsv, welche wir im Rahmen des Kapitels 3.5 erstellt haben.
Konfiguration des Solr Schemas
Anhand des Kapitel 4.4 haben wir unser Solr Schema konfiguiert, da Solr ein voreingestelltes Schema für den Suchindex.
Im ersten Schritt haben wir das Schema über Admin-Oberfläche konfiguriert. Dafür haben wir folgende Punkte durchgearbeitet.
- Admin-Oberfläche aufrufen. Im Menü „Core Selector“ den Index „htw“ auswählen. Dann im zweiten Menü „Schema“ aufrufen
- Button „Add Field“ drücken
- Name eingeben (Groß- und Kleinschreibung ist wichtig)
field type(z.B. string) auswählen- ggf. die Checkbox
multivaluedmarkieren, wenn das Feld mehrere Werte (getrennt durch ein Trennzeichen) enthält
Es erscheint eine Fehlermeldung beim Laden der Daten bzw. beim Feld date. Diese Meldung erscheint, da für dieses Feld als Standardwert UUUU angegeben ist.
Über Solr Admin löschen wir das Feld date und erstellen ein neues Feld mit dem Namen date. Zuerst ist dieses Feld im Format string aber dies funktioniert nicht. Deshalb wählen wir das Format text_general und mit diesem Format ist Solr nun endlich zufrieden.
Damit unsere Änderungen wirksam werden, müssen wir die Daten erneut indexieren.
Im ersten Schritt wird der Index mit folgendem Befehl geleert:
curl "http://localhost:8983/solr/htw/update?commit=true" -H "Content-Type: text/xml" --data-binary '<delete><query>*:*</query></delete>'
Im zweiten Schritt indexieren wir unsere einstein.tsv-Datei:
curl "http://localhost:8983/solr/htw/update/csv?commit=true&separator=%09&split=true&f.contributor.separa
In dieser Unterrichtseinheit haben wir den Suchindex konfiguriert und beim nächsten Mal machen wir uns daran unsere Daten nutzerfreundlich auf einer Katalogoberfläche darzustellen.
